Research
Our research revolves around robot behaviour. We design systems and algorithms to bring useful autonomous robots in our everyday life, capable of long-term, rational, and adaptive behaviour. Here, we summarise our research lines. Many of the publications below are from work conducted at the University of Texas at Austin, where Matteo was a post-doc with Prof. Peter Stone. A full list of publications is available on Google Scholar, and Research Gate.
Curriculum Learning in Reinforcement Learning
 Humans teach every task of significant complexity by breaking it down into a series of simpler tasks, of increasing difficulty, for the student to go through as their skills progress. Our striking ability to generalize allows us to understand the underlying principle of a problem on a simple instance, and then to apply it to a much more complex one. We study how this form incremental learning can be applied to autonomous agents, and how the agents can design their own curriculum for a particular target task.
Humans teach every task of significant complexity by breaking it down into a series of simpler tasks, of increasing difficulty, for the student to go through as their skills progress. Our striking ability to generalize allows us to understand the underlying principle of a problem on a simple instance, and then to apply it to a much more complex one. We study how this form incremental learning can be applied to autonomous agents, and how the agents can design their own curriculum for a particular target task.
We focus on algorithms for curriculum generation and refinement.
Publications:
- Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey (pdf)
- Curriculum learning with a progression function (pdf)
- Curriculum learning for cumulative return maximization (pdf)
- An optimization framework for task sequencing in curriculum learning (pdf)
- A gray-box approach for curriculum learning (pdf)
- Automatic Curriculum Graph Generation for Reinforcement Learning Agents (pdf),
- Source Task Creation for Curriculum Learning (pdf),
- Learning inter-task transferability in the absence of target task samples (pdf).
Meta-Reinforcement Learning
In meta-reinforcement learning the objective is to gather information over multiple tasks so as to speed up learning in new, similar tasks. We considered the problem of learning from a small sample of training tasks, and the use of meta-RL to form heuristics for planning.
Publications:
- Meta-Reinforcement Learning for Heuristic Planning (pdf)
- Information-theoretic Task Selection for Meta-Reinforcement Learning (pdf)
Service Robots
We work on several aspects of service robotics, but with mostly focus on: long-term autonomy and adaptation, human-robot interaction, and skill learning and manipulation (in collaboration with Dr Mehmet Dogar). Also see our LASR team page.
Publications:
- Human-like planning for reaching in cluttered environments (pdf)
- Occlusion-Aware Search for Object Retrieval in Clutter (pdf)
- Learning image-based Receding Horizon Planning for manipulation in clutter
- Learning Physics-Based Manipulation in Clutter: Combining Image-Based Generalization and Look-Ahead Planning (pdf)
- Planning with a Receding Horizon for Manipulation in Clutter using a Learned Value Function (pdf)
- BWIBots: A platform for bridging the gap between AI and human–robot interaction research.(pdf)
Robust high-level decision making for mobile robots
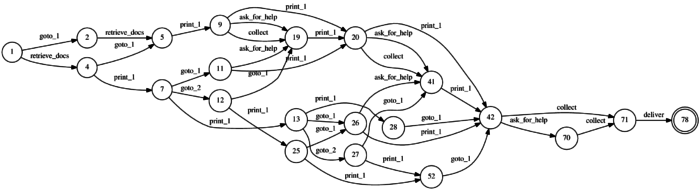 Automated Planning is a formidable tool, but it is only as good as the model of the environment it uses, which inevitably is an approximation of the real world meant to balance computational complexity, human intervention, and accuracy. As a consequence, robots have a hard time acting in the real world (as opposed to our controlled labs) for long periods of time, when the assumptions they have been programmed with are eventually violated. Machine learning, and in particular reinforcement learning, is also a formidable tool, which allows the agent to learn from experience, and constantly adapt to the environment. Real experience, however, creates real bruises, and real robots are limited in the amount of experience they can gather. Striking a balance between the two is the objective of this research line.
Automated Planning is a formidable tool, but it is only as good as the model of the environment it uses, which inevitably is an approximation of the real world meant to balance computational complexity, human intervention, and accuracy. As a consequence, robots have a hard time acting in the real world (as opposed to our controlled labs) for long periods of time, when the assumptions they have been programmed with are eventually violated. Machine learning, and in particular reinforcement learning, is also a formidable tool, which allows the agent to learn from experience, and constantly adapt to the environment. Real experience, however, creates real bruises, and real robots are limited in the amount of experience they can gather. Striking a balance between the two is the objective of this research line.